 Thomas Pain 1791, Picture Credit: Bassett Publishing
Thomas Pain 1791, Picture Credit: Bassett Publishing
Introduction
Common-sense reasoning (CSR) is one of the branches of artificial intelligence (AI) that is concerned with simulating the human ability to make assumptions about the type and essence of ordinary situations they encounter every day including judgments about the physical properties, purpose, intentions and behavior of people and objects, as well as possible outcomes of their actions and interactions. An intelligent machine which exhibits common-sense reasoning will be capable of predicting results of people’s behavior and intentions and their perception of humans’ natural understanding of the physical world.
Common-sense knowledge (CSK) is the set of background information that an individual is intended to know or assume and the ability to use it when appropriate. It is a shared knowledge (between everybody or people in a particular culture or age group only). The way to obtain common-sense knowledge is by learning it or experiencing it. Humans have the advantage that their bodily sensual experience based on sound, smell, vision, touch and taste is processed and stored by the brain’s cognitive capability in real-time without the need for labelling huge datasets.
According to Niket Tandon from the Allen Institute for Artificial Intelligence one can partition common-sense into three dimensions: (a) Common-sense relating to objects in the environment, including properties, theories (such as physics), and associated emotions; (b) Common-sense relating to object relationships, including taxonomic, spatial and structural relationships among the objects and (c) Common sense relating to interactions, including actions, processes, and procedural knowledge.
The problem of creating a CSK database
The problem of CSK is to create a database that contains the general knowledge most individuals are expected to have, represented in an accessible way to artificial intelligence programs that use natural language. Due to the broad scope of the common-sense knowledge, this topic is among the most difficult in the AI research sphere. Although intelligent machines can defeat the best human Go players, drive cars, answer natural language inquiries about the weather or other specific topics, they do not actually understand what they are doing. Their success has been achieved primarily through multi-level artificial neural networks (Deep Learning) which achieve their best results by gobbling up vast amounts of labelled training data (datasets) in combination with so-called ‘back-propagation’, an algorithm which is used to train neural networks to reach a specific result.
Common-sense knowledge differs from encyclopaedic knowledge in that it deals with general knowledge rather than the details of specific entities. Most regular knowledge datasets contribute millions of facts about entities, such as people or geopolitical entities, but fail to provide fundamental knowledge, such as the notion that a baby is probably too young to have a doctoral degree in physics. The challenges in acquiring CSK include its elusiveness and context-dependence. Common-sense is
elusive because it is scarcely and often only implicitly expressed. Context plays an important role for common-sense in defining its correctness, and this must be accounted for while acquiring it.
The trouble with common-sense applications is that one cannot experiment with it until one has a large common-sense database. In 1985 Doug Lenat, at that time a young professor at Stanford, started to build-up a handcrafted database called Cyc to classify and store common-sense knowledge. Since that time Lenat and his colleagues have been spending years feeding common-sense knowledge into Cyc. 33 years later, following a 2000 man-year effort, building a common-sense application with Cyc still requires a significant engineering effort. The trouble is that Cyc is difficult to use, it is proprietary and so far, not much used by researchers. To overcome this problem researchers have started to apply datamining to find common-sense relationships from textual analysis of specific scenarios combined with neural net labelling.
A state-of-the-art example to build a CSK Database
In a paper published in May 2018, titled ‘Modelling Naive Psychology of Characters in Simple Common-Sense Stories’, Hannah Rashkin and her colleagues from the University of Washington, introduce a new annotation (labelling) framework to explain naive psychology of story characters as fully-specified chains of mental states with respect to motivations and emotional reactions. Their dataset to date includes a total of 300’000 low-level annotations for character motivations and emotional reactions across 15,000 stories as a resource for training and evaluating mental state tracking of characters in short common-sense stories. Importantly, they show that modelling character-specific context improves labelling performance. They view their dataset as a future testbed for evaluating models trained on any number of resources for learning common sense about emotional reactions and motivations.
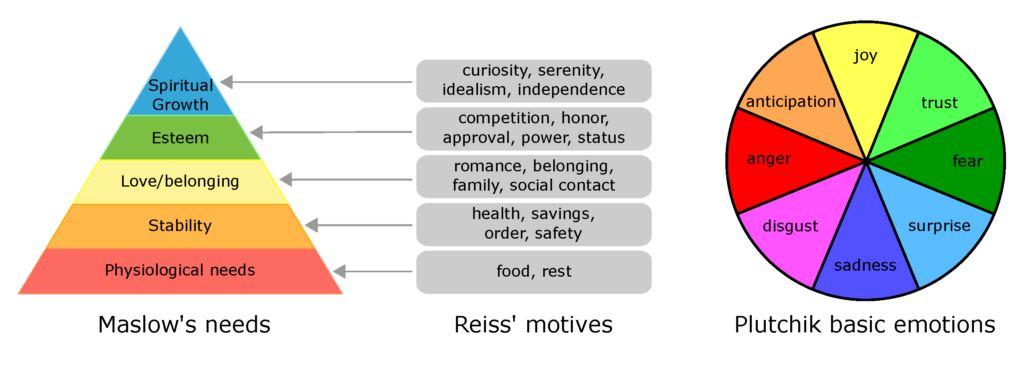
To classify the motivation of the story characters, they use two popular theories of motivation: the “hierarchy of needs” of Maslow and the “basic motives” of Reiss. Maslow’s “hierarchy of needs” is comprised of five categories, ranging from physiological needs to spiritual growth, which they use as base-level categories. Reiss proposes 19 more fine-grained categories that provide a more informative range of motivations. To classify the emotions of the story characters, they work with the “wheel of emotions” of Plutchik, with eight basic emotional dimensions, as it has been a common choice in prior literature on emotion categorization. In addition to the motivation and emotion
categories derived from psychology theories, they also obtain open text descriptions of characters’ mental states. These open text descriptions allow computational models that can learn and explain the mental states of characters in natural language, which is likely to be more accessible and informative to end users than having theory categories alone.
Next steps to achieve CSR
There are two major schools of thought in common-sense reasoning. One side works with more logic-like or rule-based representations, while the other uses more associative and analogy-based reasoning or “language-based” common-sense — the latter of which draws conclusions that are fuzzier but closer to the way that natural language works. None of these two schools so far has succeeded in taking the lead in reaching AI-based CSR. In fact, one could take a philosophical view that a broader horizon beyond logical science is needed to solve this problem.
Rudolf Carnap, a German-born philosopher and former Professor at UCLA, was one of the major philosophers of the twentieth century. He made significant contributions to philosophy of science, philosophy of language and the theory of probability. Back in 1966, he wrote, “What good are scientific laws? What purposes do they serve in science and everyday life? The answer is twofold: they are used to explain facts already known, and they are used to predict facts not yet known.”
At the Cognitive Computational Neuroscience (CCN) conferences that took place in New York City last year, more than half a century after these words were published, Josh Tenenbaum, Professor of Cognitive Science at MIT, reflected on Carnap’s work as he spoke about the importance of developing AI with a human ability to model the world. Humans learn and predict using scientific laws that are translated into common-sense — these laws range from universal physical laws (if the cup tips, milk will spill; if the ball drops, it will fall to the ground) to complex social laws (what are the consequences if I commit a crime?).
Back in 1966 Carnap also wrote, “In many cases, the laws involved may be statistical rather than universal. The prediction will then be only probable.” Tenenbaum, following the ideas of Carnap, uses Bayesian Theory, a form of inductive logic, to model these probabilities and supplement traditional Deep Learning with physical and social models of the world. When the brain models a physical or social law, whether causal or statistical, the model acts as a template to facilitate prediction. Prediction constitutes a key element of common-sense. “Intelligence is not just about pattern recognition,” says Tenenbaum. “The mind is a modelling engine.” At a glance, humans can perceive whether a stack of dishes will topple, a branch will support a child’s weight … or if a tool is firmly attached to a table or free to be lifted. Such rapid physical inferences are central to how people interact with the world and with each other, yet their computational underpinnings are poorly understood. Hence Tenenbaum and his colleagues are in the initial stages of fusing Deep Learning with physical and social models to build cognitive systems they call probabilistic programs for achieving CSR.
Conclusion
CSR is a major stepping-stone in reaching Artificial General Intelligence (AGI). Many experts from the AI-community, like Geoffrey Hinton, considered the ‘grandfather’ of neural networks, or Demis Hassabis from Google DeepMind agree, that we need new concepts that go beyond Deep Learning and back-propagation. From the issues discussed in this essay, one could conclude that a hybrid approach, combining machine learning with common-sense mind modelling, could advance the state-of-the-art in CSR. While machine learning delivers outstanding results to solve specific tasks of intelligence, CSR could be applied as a ‘second opinion’ to predict if the machine-learning results really make sense. Having reached that level, the question resurfaces concerning the role of human beings in a world where implicit or explicit intelligence is a commodity available to anyone. Considering the exponential speed at which AI research is advancing, it seems likely that AI will match humans in common-sense reasoning by 2030.
why not put everything in a list and then if it is not or
it is not a word in that category then say no it is not.
ai could scrape facts about a certain thing in a categories from wikipedia. then use that to give a reason why something is what it is.