 Writing the Declaration of Independence / Picture Credit: Wikipedia
Writing the Declaration of Independence / Picture Credit: Wikipedia
Introduction
Language is one of the most important means of communication and elemental for the existence of modern societies, institutions, states and cultures. Its resourcefulness allows humans to establish social relationships and design new forms of cooperation. It is a robust and highly optimized form of communication and for thousands of years language has been a tool for social interaction. Humanity depends on the capacity of language to communicate complex, new ideas, integrating them into the design of new products and services. This can only be achieved by concerted efforts of collaboration. To work together, people need language.
The Emergence of Natural Language Processing (NLP)
The processing of human language with computers, is not a new discipline. Some date it back to 1950, with Alan Turing’s famous test which a machine would pass by holding a convincingly “human” conversation, something which yet remains to be accomplished. Others like J.R. Firth stated in 1957 that to understand the meaning of a word, we must look at its context. Natural language processing (NLP) is generally defined as the field of artificial intelligence that aims to understand and generate human – natural – language. A dialogue with a human was regarded by Turing as the paramount of AI complexity. For a machine to hold a natural conversation requires the ability to overcome the intrinsic ambiguity of human language. The foundational concept of NLP is that the meaning of a word is determined by the words around it since similar words will appear in similar contexts. To exploit this intuitive notion of similarity in practical applications such as search engines or e-mail writing assistants, the AI research community has created the vector space model, a representation of words as vectors in a multi-dimensional space enabling an easy computation of word similarity. Due to the overlap with other domains of artificial intelligence, enumerating all NLP applications is not easy. The bulk of the applications, however, are combinations of one or more of three basic tasks as defined by the following table:

What is Natural Language Generation (NLG)?
Natural Language Generation is the “process of producing meaningful phrases and sentences in the form of natural language.” It generates narratives that describe, summarize or explain structured data. NLP converts text into structured data while NLG generates a universally understandable text, making the writing of data-driven financial reports, product descriptions, or meeting memos more efficient. Ideally, it takes the burden of summarizing data assembled by analysts to automatically generate reports that can be tailored to a specific audience. In the attempts to mimic human speech, NLG systems require computational training from huge datasets as provided by Wikipedia, specialized libraries or topic-oriented conversations which are extruded from the internet with so-called crawler-software. Over the last two decades several AI models have been developed to support the generation of natural language applications:
Markov chain model
This model predicts the next word in the sentence by using the current word and considering the relationship between each unique word to calculate the probability of the next word. In early versions of the smartphone keyboard, this language model was used to generate suggestions for the next word in the sentence.
Recurrent neural network (RNN) model
RNNs pass each item of a word sequence through a feedforward network and use the output of the model as input to the next item in the sequence. In each iteration, the model stores the previous words encountered in its memory and calculates the probability of the next word. For each word in the dictionary, the model assigns a probability based on the previous word, selects the word with the highest probability and stores it in memory.
Transformer Model
This relatively new model was first introduced in 2017 by Google. Unlike previous models, the Transformer uses the representation of all words in context without having to compress all the information into a single fixed-length representation. The transformer concept has gained wide acceptance for NLG products and services, for example, Google’s product BERT or OpenAI’s widely publicized product GPT-2. Both analyse thousands of self-published books, including romance novels, science fiction stories or Wikipedia libraries. Conceptionally GPT-2 learns to guess the next word in a sentence while BERT learns to guess missing words anywhere in a sentence, generating a sequence of natural language about a preselected topic.
The future of NLG
These days and probably for quite some time to come, NLG represents one of the hottest AI-research activities to follow. As language models are continuously improved, hardly a month goes by without the publication of new and better tools to enhance the quality of NLG applications. Several big-tech companies are engaged in a competitive race to strive for market domination. As the processing of large neural networks demands huge computational resources, the exponentially growing performance of new computer hardware is supporting this trend as well. With strong financial and technical support from Microsoft, OpenAI just announced GPT-3 as successor to GPT-2. The new offering includes an API, supporting the design of specific applications such as:
- Semantic search based on the meaning of queries rather than the matching of keywords.
- Leveraging search and chat capabilities to generates natural dialogues.
- Inducing text into spreadsheet tables for report writing.
- Expanding content from bullet points to create narratives.
To support these applications, GPT-3 has been expanded to a staggering 175 billion parameters from the ‘modest’ 1.5 billion provided by GPT-2. A parameter in this context is defined as a calculation within a neural network that applies a weight-factor to some aspect of the text in order to give that aspect greater or lesser prominence in the overall analysis of the entire text. These weights provide the neural network with a learned perspective of the text, generating natural language as output. Like GPT-2 and other Transformer-based models, GPT-3 is trained on the Common-Crawl data set, a corpus of almost a trillion text combinations extruded from the Web. Despite the realization that bigger may not ultimately be better, the improved results of GPT-3 are likely to fuel the desire for bigger and bigger neural networks. Currently, with 175 billion parameters, GPT-3 is one of the largest neural networks. Yet, critically assessing its own accomplishment, OpenAI also states that “With GPT-3’s self-supervised objectives, task specification relies on forcing the desired task into a prediction problem, whereas ultimately, useful language systems (for example virtual assistants) might be better in taking goal-directed actions rather than just making predictions. Just making the neural network ever-more-powerful and stuffing it with ever-more-text may not yield better results.”
Handling Context: From Deep-Learning to Deep-Understanding
Applications which rely on well-structured data are likely to benefit from the advancement in NLG technology. However, there are major hurdles ahead as common-sense reasoning cannot be created with brute-force computation of massive data alone. What computational prerequisites would we need to have systems that are capable of reasoning ? It is a fallacy to suppose that what worked reasonably well for domains such as speech recognition and object labelling will necessarily work reliably for language comprehension and higher-level reasoning. In his paper ‘The Next Decade in AI’, published in February 2020, Gary Marcus and his collaborator Ernest Davis suggest a recipe for achieving common sense, and ultimately general intelligence:
“Start by developing systems that can represent the core frameworks of human knowledge: time, space, causality, basic knowledge of physical objects and their interactions, basic knowledge of humans and their interactions. Embed these in an architecture that can be freely extended to every kind of knowledge, keeping always in mind the central tenets of abstraction, compositionality, and tracking of individuals. Develop powerful reasoning techniques that can deal with knowledge that is complex, uncertain, and incomplete and that can freely work both top-down and bottom-up. Connect these to perception, manipulation, and language. Use these to build rich cognitive models of the world. Then finally the keystone: construct a kind of human-inspired learning system that uses all the knowledge and cognitive abilities that the AI has; that incorporates what it learns into its prior knowledge; and that, like a child, voraciously learns from every possible source of information: interacting with the world, interacting with people, reading, watching videos, even being explicitly taught. Put all that together, and that’s how you get to deep-understanding.”
That said, this approach might lead to self-teaching machines with an incomplete understanding of the world but a powerful talent for acquiring new ideas.
Conclusion
Several decades ago, doing a math calculation by hand on a piece of paper was a highly appreciated skill. Today internet-based communication and on-line interactions require a new set of skills. But what happens when AI gets applied in communication tasks? There is a risk that some humans might resign from their intellect and sit on the side-lines, waiting for their smartphone app to tell them what to do next and how they might be feeling now! This depressing scenario has been addressed by the historian Yuval Noah Harari in his book ‘Homo Deus’: not intelligent machines but dumb humans are our problem. To take advantage of AI, we should induce the creative capacity of our intelligence. In the context of language and writing, we must distinguish between computer-generated textual representations of facts and the creative process of formulating an idea or a story, something we might also refer to as ‘thoughtful writing’. The combination of thinking and writing helps us to augment and foster our intelligence in an iterative process as depicted by the following graph:
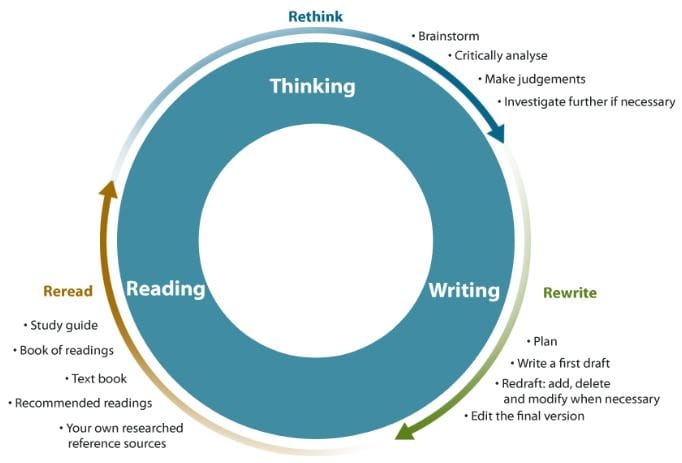
Thoughtful writing is a highly individualized process. We reread what we wrote, and just like any reading, this further induces more thinking about the purpose of our writing, enhancing our knowledge and our ability to communicate the outcome in a trustful, convincing fashion. Reading stipulates searching for information. Common-sense reasoning, supported by intelligent machines, will greatly facilitate this process. But it cannot replace the motivation and purpose of thoughtful writing as a vital element of a ‘living’ society, fostering the wellbeing of its members by trusted communication.
Hello Peter,
your exceptional essays are clear results of thoughtful writing which is very personal as you outline.
When reading each of your essays I clearly perceive the very high level of trustworthiness,
wide experience, expert knowledge (dynamic enhancing, researching) you transmit together with
your positive personal human direction in a perceivable essay vehicle.
Besides the intellectual value of your essays, probably not only for me, they also contribute to ‘well-being’ in the actual times with massive superficial info (fragment) overload, redundancies and biases. (Mathematical(or psychological): solid pattern and vector in the chaotic overall context, Human: Compassion).
many thanks and best greetings Hannes